写在前面
你有没有遇到过这样的尴尬:
你: ChatGPT,我们公司最新的产品政策是什么?
ChatGPT: 抱歉,我的训练数据只到2023年10月,
无法回答关于贵公司最新政策的问题...
你: (╯°□°)╯︵ ┻━┻ 你是AI助手啊!怎么连公司文档都不知道?这就是大语言模型的典型困境:它只知道训练时见过的东西,对专有数据、实时信息、特定领域知识一无所知。
传统解决方案是微调(Fine-tuning)——重新训练模型让它记住新知识。但问题是:
- 💸 成本高昂 - 每次更新都要重新训练
- ⏱️ 耗时漫长 - 训练周期以天甚至周计算
- 🔧 技术门槛高 - 需要专业的ML工程师
- 📝 更新不便 - 知识一变就得重新来过
有没有更优雅的方案?
有!那就是RAG(Retrieval-Augmented Generation,检索增强生成)。
今天这篇文章将带你彻底搞懂:
- RAG是什么,为什么说它像"开卷考试"
- RAG的完整工作流程(检索→增强→生成)
- 如何用LangChain + Weaviate + OpenAI从零搭建RAG系统
- 完整的代码实现和最佳实践
RAG的天才类比:从闭卷到开卷
传统LLM = 闭卷考试
想象你参加一场闭卷考试:
考试规则:
- 只能依靠记忆作答
- 不能查阅任何资料
- 考前疯狂死记硬背
结果:
✅ 记住的知识 → 答对
❌ 没记住的知识 → 瞎编(幻觉)这就是传统LLM的状态:所有知识都要"背"进神经网络权重里,记不住就只能胡编。
RAG = 开卷考试
现在想象考试规则变了,允许你开卷考试:
考试规则:
- 可以带参考书、笔记
- 遇到问题先翻书查资料
- 基于查到的内容作答
结果:
✅ 推理能力 + 准确的参考资料 → 高质量答案
✅ 资料随时可更新,无需重新"背书"这就是RAG的核心思想!
RAG = 给AI一个"外挂的知识库" + 允许它"翻书作答"
知识的两种形式
| 知识类型 | 存储位置 | 特点 | 类比 |
|---|---|---|---|
| 参数化知识 | 神经网络权重 | 训练时学到,隐式存储 | 脑子里背的知识 |
| 非参数化知识 | 外部数据库 | 独立存储,可随时更新 | 参考书、笔记本 |
RAG的关键创新: 将知识从"参数"转移到"外部",实现了知识与推理的分离。
RAG的三大优势
优势1: 解决幻觉问题
问题场景:
# 没有RAG
问: 总统对布雷耶大法官说了什么?
答: 抱歉,我的训练数据只到2022年1月,
无法回答这个问题... (或者开始瞎编)# 使用RAG
问: 总统对布雷耶大法官说了什么?
系统内部:
1. 检索 → 从2022年国情咨文中找到相关段落
2. 增强 → 将段落作为上下文提供给LLM
3. 生成 → 基于上下文准确回答
答: 总统感谢布雷耶大法官的服务,
并提名Ketanji Brown Jackson作为继任者...优势2: 知识更新便捷
| 维度 | 微调 | RAG |
|---|---|---|
| 更新成本 | 高(重新训练) | 低(更新数据库) |
| 更新速度 | 慢(天/周) | 快(分钟/秒) |
| 技术要求 | 需要ML专家 | 普通开发者可操作 |
| 灵活性 | 低 | 高 |
优势3: 支持专有数据
适用场景:
✅ 公司内部文档和知识库
✅ 实时新闻和动态信息
✅ 特定领域的专业知识
✅ 用户个人数据和偏好RAG工作流程完全解析
RAG的完整流程可以分为三个核心步骤:
流程示意图
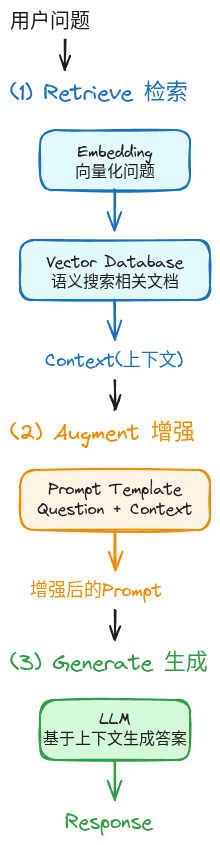
步骤1: Retrieve(检索)
目标: 从知识库中找出与问题最相关的内容。
工作原理:
# 1. 将用户问题向量化
user_question = "总统对布雷耶大法官说了什么?"
question_embedding = embedding_model.encode(user_question)
# 输出: [0.123, -0.456, 0.789, ...] (一个高维向量)
# 2. 在向量数据库中搜索最相似的文档
similar_docs = vector_db.similarity_search(
query_embedding=question_embedding,
top_k=3 # 返回最相关的3个文档片段
)
# 3. 得到相关上下文
context = "\n\n".join([doc.content for doc in similar_docs])关键技术:
- 向量嵌入(Embedding) - 将文本转换为数学向量
- 语义搜索 - 基于含义而非关键词匹配
- 向量数据库 - 高效存储和检索向量
步骤2: Augment(增强)
目标: 将检索到的上下文与用户问题组合成完整的Prompt。
Prompt模板示例:
template = """
你是一个问答助手。
请基于以下上下文回答问题。
如果上下文中没有相关信息,请明确说"我不知道"。
上下文:
{context}
问题: {question}
答案:
"""
# 填充模板
augmented_prompt = template.format(
context=context,
question=user_question
)增强前 vs 增强后:
❌ 增强前:
总统对布雷耶大法官说了什么?
✅ 增强后:
你是一个问答助手。
请基于以下上下文回答问题。
上下文:
[2022年国情咨文片段]
"今晚,我想向一位奉献一生为国家服务的人致敬——
布雷耶大法官。我提名了联邦上诉法院法官Ketanji Brown Jackson
来继续布雷耶大法官的卓越传统..."
问题: 总统对布雷耶大法官说了什么?
答案:步骤3: Generate(生成)
目标: LLM基于增强后的Prompt生成准确答案。
# 调用LLM
response = llm.generate(augmented_prompt)
# 输出
print(response)
# "总统感谢布雷耶大法官的服务,
# 并提名Ketanji Brown Jackson作为继任者,
# 以延续其卓越传统。"关键特点:
- ✅ 答案基于提供的上下文,减少幻觉
- ✅ 可追溯答案来源
- ✅ LLM专注于推理而非记忆
数据准备:构建知识库
在实现RAG之前,需要先准备好向量数据库。
三步走流程
原始文档
↓
收集并加载
↓
文档分块
↓
向量化并存储
↓
向量数据库 ✅步骤1: 收集并加载数据
import requests
from langchain.document_loaders import TextLoader
# 下载示例文档(拜登2022年国情咨文)
url = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
# 使用LangChain加载文档
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
print(f"加载了{len(documents)}个文档")LangChain支持的加载器:
TextLoader- 纯文本文件PDFLoader- PDF文档CSVLoader- CSV数据WebBaseLoader- 网页内容NotionDBLoader- Notion数据库- ...还有100+种加载器
步骤2: 文档分块
为什么要分块?
问题: 原始文档太长(如10万字的技术手册)
❌ 直接输入LLM:
- 超出上下文窗口限制
- 包含大量无关信息
- 成本高昂
✅ 分成小块:
- 只检索相关片段
- 精准匹配用户问题
- 降低成本代码实现:
from langchain.text_splitter import CharacterTextSplitter
# 创建分块器
text_splitter = CharacterTextSplitter(
chunk_size=500, # 每块约500字符
chunk_overlap=50 # 块间重叠50字符,保持连贯性
)
# 执行分块
chunks = text_splitter.split_documents(documents)
print(f"文档被分成{len(chunks)}个片段")
# 查看第一个片段
print(chunks[0].page_content)分块参数调优:
| 参数 | 建议值 | 说明 |
|---|---|---|
chunk_size | 500-1000 | 太小→上下文不足;太大→不精准 |
chunk_overlap | 50-100 | 保持块间连贯性 |
步骤3: 向量化并存储
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
# 初始化Weaviate客户端
client = weaviate.Client(
embedded_options=EmbeddedOptions()
)
# 创建向量数据库并自动填充
vectorstore = Weaviate.from_documents(
client=client,
documents=chunks, # 文档片段
embedding=OpenAIEmbeddings(), # 使用OpenAI嵌入模型
by_text=False
)
print("向量数据库创建完成!")幕后发生了什么?
# 对每个文档片段:
for chunk in chunks:
# 1. 生成向量嵌入
embedding = OpenAIEmbeddings().embed_query(chunk.content)
# 2. 存储到向量数据库
vectorstore.add(
text=chunk.content,
embedding=embedding,
metadata=chunk.metadata
)完整RAG实现:LangChain版
现在让我们把所有组件组装起来!
环境准备
# 安装依赖
pip install langchain openai weaviate-client
# 设置环境变量
export OPENAI_API_KEY="your-api-key-here"import dotenv
dotenv.load_dotenv() # 加载.env文件中的API密钥完整代码实现
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
import weaviate
from weaviate.embedded import EmbeddedOptions
# ========== 1. 数据准备 ==========
# 加载文档
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
# 文档分块
text_splitter = CharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)
# 创建向量数据库
client = weaviate.Client(
embedded_options=EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client=client,
documents=chunks,
embedding=OpenAIEmbeddings(),
by_text=False
)
# ========== 2. 构建RAG链 ==========
# 步骤1: 定义检索器
retriever = vectorstore.as_retriever()
# 步骤2: 定义Prompt模板
template = """你是一个用于问答任务的助手。
使用下面检索到的上下文片段来回答问题。
如果你不知道答案,只需说你不知道。
最多使用三个句子,并保持回答简洁。
问题: {question}
上下文: {context}
答案:
"""
prompt = ChatPromptTemplate.from_template(template)
# 步骤3: 定义LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# 步骤4: 组装RAG链
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
# ========== 3. 使用RAG系统 ==========
# 提问
query = "What did the president say about Justice Breyer?"
response = rag_chain.invoke(query)
print(response)输出结果:
The president thanked Justice Breyer for his service
and acknowledged his dedication to serving the country.
The president also mentioned that he nominated Judge
Ketanji Brown Jackson as a successor to continue Justice
Breyer's legacy of excellence.代码详解
1. LangChain的链式语法
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)理解这个"管道":
# 等价于:
def rag_chain(question):
# 步骤1: 检索
context = retriever.invoke(question)
# 步骤2: 增强
augmented_prompt = prompt.format(
context=context,
question=question
)
# 步骤3: 生成
llm_response = llm.invoke(augmented_prompt)
# 步骤4: 解析输出
final_answer = str_output_parser.parse(llm_response)
return final_answer2. 关键组件说明
| 组件 | 作用 | 代码 |
|---|---|---|
| Retriever | 检索器 | vectorstore.as_retriever() |
| Prompt Template | 模板 | ChatPromptTemplate.from_template() |
| LLM | 语言模型 | ChatOpenAI() |
| Output Parser | 输出解析 | StrOutputParser() |
进阶优化技巧
技巧1: 调整检索参数
# 调整返回的文档数量
retriever = vectorstore.as_retriever(
search_kwargs={"k": 5} # 返回Top 5最相关文档
)
# 使用MMR(最大边际相关性)检索
retriever = vectorstore.as_retriever(
search_type="mmr", # 使用MMR算法
search_kwargs={
"k": 5, # 返回5个文档
"fetch_k": 20, # 从20个候选中选择
"lambda_mult": 0.5 # 多样性参数(0=最大多样性,1=最大相关性)
}
)技巧2: 优化Prompt模板
# 添加更多指令
template = """你是一个专业的问答助手。
使用规则:
1. 仅基于提供的上下文回答
2. 如果上下文不足,明确说"根据提供的信息无法回答"
3. 如果需要推断,请说明"基于上下文推断..."
4. 保持简洁,最多3句话
5. 如果可能,引用具体的上下文片段
上下文:
{context}
问题: {question}
答案:
"""技巧3: 添加来源追溯
from langchain.schema.runnable import RunnableParallel
# 改进的RAG链,保留来源信息
rag_chain_with_source = RunnableParallel(
{
"context": retriever,
"question": RunnablePassthrough()
}
).assign(
answer=prompt | llm | StrOutputParser()
)
# 使用
result = rag_chain_with_source.invoke(query)
print("答案:", result["answer"])
print("\n来源文档:")
for i, doc in enumerate(result["context"], 1):
print(f"{i}. {doc.page_content[:100]}...")技巧4: 添加缓存机制
from functools import lru_cache
@lru_cache(maxsize=100)
def cached_retrieve(question: str):
"""缓存检索结果"""
return retriever.invoke(question)
# 在RAG链中使用缓存
rag_chain = (
{"context": cached_retrieve, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)生产环境最佳实践
实践1: 构建健壮的RAG系统
class ProductionRAGSystem:
"""生产级RAG系统"""
def __init__(self, vectorstore, llm):
self.vectorstore = vectorstore
self.llm = llm
self.retriever = vectorstore.as_retriever(
search_kwargs={"k": 3}
)
def answer(self, question: str) -> dict:
"""
回答问题并返回详细信息
"""
try:
# 检索
docs = self.retriever.get_relevant_documents(question)
if not docs:
return {
"answer": "抱歉,未找到相关信息",
"sources": [],
"confidence": 0.0
}
# 构建Prompt
context = "\n\n".join([doc.page_content for doc in docs])
prompt = f"""
基于以下上下文回答问题。
上下文:
{context}
问题: {question}
答案:
"""
# 生成答案
answer = self.llm.invoke(prompt).content
# 评估置信度(简化版)
confidence = self._estimate_confidence(answer, docs)
return {
"answer": answer,
"sources": [doc.metadata for doc in docs],
"confidence": confidence
}
except Exception as e:
return {
"answer": "系统错误,请稍后重试",
"error": str(e),
"confidence": 0.0
}
def _estimate_confidence(self, answer: str, docs: list) -> float:
"""
估计答案置信度
"""
# 简化实现:基于检索文档的相似度分数
if not docs:
return 0.0
# 实际应用中可以使用更复杂的方法
avg_score = sum([d.metadata.get('score', 0.5) for d in docs]) / len(docs)
return avg_score实践2: 监控与日志
import logging
from datetime import datetime
# 配置日志
logging.basicConfig(
filename='rag_system.log',
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s'
)
def log_rag_interaction(question, answer, sources, latency):
"""记录RAG交互"""
logging.info({
"timestamp": datetime.now().isoformat(),
"question": question,
"answer": answer[:100], # 只记录前100字符
"num_sources": len(sources),
"latency_ms": latency * 1000
})实践3: 成本优化
# 策略1: 使用更便宜的嵌入模型
from langchain.embeddings import HuggingFaceEmbeddings
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2"
) # 本地运行,零成本
# 策略2: 批量处理
def batch_embed(texts, batch_size=32):
"""批量生成嵌入,提高效率"""
embeddings_list = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i+batch_size]
batch_embeddings = embeddings.embed_documents(batch)
embeddings_list.extend(batch_embeddings)
return embeddings_list
# 策略3: 使用缓存减少API调用
from langchain.cache import InMemoryCache
from langchain.globals import set_llm_cache
set_llm_cache(InMemoryCache())RAG vs 微调:如何选择?
对比表
| 维度 | RAG | 微调 |
|---|---|---|
| 知识更新 | ⭐⭐⭐⭐⭐ 实时 | ⭐⭐ 需重新训练 |
| 实施成本 | ⭐⭐⭐⭐ 较低 | ⭐⭐ 较高 |
| 技术门槛 | ⭐⭐⭐⭐ 较低 | ⭐⭐ 需ML专家 |
| 回答准确性 | ⭐⭐⭐⭐ 基于事实 | ⭐⭐⭐⭐⭐ 内化知识 |
| 可解释性 | ⭐⭐⭐⭐⭐ 可追溯来源 | ⭐⭐ 黑盒 |
| 响应延迟 | ⭐⭐⭐ 需检索 | ⭐⭐⭐⭐⭐ 直接生成 |
选择建议
✅ 优先选择RAG的场景:
- 知识频繁更新(如新闻、政策)
- 需要可追溯性和可解释性
- 多租户系统(每个用户不同知识库)
- 预算有限,技术团队规模小
✅ 考虑微调的场景:
- 需要改变模型行为或风格
- 知识相对稳定
- 对延迟要求极高
- 有充足的训练数据和预算
✅ 最佳实践:两者结合
- 微调:调整模型风格、指令遵循能力
- RAG:提供事实性知识和最新信息常见问题与解决方案
问题1: 检索不准确
症状: 检索到的文档与问题不相关
解决方案:
1. 调整chunk_size和overlap
2. 改进嵌入模型(使用领域特定模型)
3. 使用混合检索(关键词+语义)
4. 添加元数据过滤代码示例:
# 解决方案4: 添加元数据过滤
retriever = vectorstore.as_retriever(
search_kwargs={
"k": 5,
"filter": {"source": "official_docs"} # 只检索官方文档
}
)问题2: 上下文太长超出限制
症状: 检索的文档总长度超出LLM上下文窗口
解决方案:
1. 减少k值(返回更少文档)
2. 使用重排序(Reranking)选择最相关文档
3. 使用支持更长上下文的模型
4. 实施分层检索问题3: 答案缺乏连贯性
症状: 来自不同文档的片段拼接后不连贯
解决方案:
1. 增加chunk_overlap保持连续性
2. 改进Prompt模板,明确要求连贯性
3. 使用文档结构信息(标题、章节)
4. 后处理:让LLM重新组织答案总结:RAG的核心价值
关键要点
-
RAG的本质
- 将知识从模型参数转移到外部数据库
- 实现知识与推理的分离
- 像"开卷考试"一样让AI查阅资料作答
-
三步工作流程
Retrieve(检索) → Augment(增强) → Generate(生成) -
核心优势
- ✅ 减少幻觉,提高准确性
- ✅ 知识更新便捷,无需重新训练
- ✅ 支持专有数据和实时信息
- ✅ 可追溯答案来源,提高可信度
-
技术栈
- 编排框架: LangChain
- 向量数据库: Weaviate, Pinecone, Chroma等
- 嵌入模型: OpenAI, HuggingFace等
- LLM: GPT-4, Claude, Llama等
实施清单
✅ 数据准备阶段:
- [ ] 收集和整理知识库文档
- [ ] 选择合适的文档加载器
- [ ] 确定分块策略(chunk_size和overlap)
- [ ] 选择嵌入模型
- [ ] 搭建向量数据库
✅ RAG系统构建:
- [ ] 实现检索器(Retriever)
- [ ] 设计Prompt模板
- [ ] 配置LLM
- [ ] 组装RAG链
- [ ] 添加错误处理
✅ 优化与监控:
- [ ] 调优检索参数
- [ ] 实施缓存机制
- [ ] 添加日志和监控
- [ ] 评估答案质量
- [ ] 持续迭代改进进阶方向
1. 高级检索技术
- 混合检索(关键词+语义)
- 重排序(Reranking)
- 查询改写(Query Rewriting)
- 多轮检索(Iterative Retrieval)
2. 答案质量提升
- Self-reflection(自我反思)
- Multi-query(多查询融合)
- HYDE(假设文档嵌入)
- Chain-of-Thought RAG
3. 系统工程化
- 分布式向量数据库
- 负载均衡和缓存
- A/B测试框架
- 自动化评估体系下一步行动
今天就试试:
- 安装LangChain和Weaviate
- 准备一些文档(公司文档、个人笔记等)
- 运行本文的完整代码示例
- 测试不同的问题,观察RAG效果
本周目标:
- 搭建自己的知识库RAG系统
- 尝试不同的chunk_size和overlap参数
- 优化Prompt模板
- 添加来源追溯功能
长期实践:
- 将RAG集成到实际应用中
- 建立评估和监控体系
- 探索高级检索技术
- 关注RAG领域最新研究
记住:RAG不是银弹,但它确实是当前最实用、最灵活的知识增强方案。
从今天开始,让你的AI助手不再"死记硬背",而是学会"翻书作答"! 📚✨
延伸阅读
这篇文章对你有帮助吗?分享你的RAG实践经验!