引言:从通用助手到领域专家
想象一下这些场景:
场景 1: 重复的上下文说明
你: "帮我分析这个 BigQuery 数据,记住要排除测试账户,使用 user_metrics 表..."
Claude: "好的,我来分析..."
[第二天]
你: "再帮我分析一次销售数据,还是那个表,记得排除测试账户..."
Claude: "好的,我来分析..." # 😓 又要重复一遍场景 2: 领域知识的重复传授
你: "帮我处理这个 PDF 表单,PDF 的表单字段结构是..."
Claude: "明白了"
[一周后]
你: "再处理一个 PDF 表单..."
Claude: "请告诉我 PDF 表单的结构" # 😓 忘记了场景 3: 工作流程的不一致
你: "生成 API 文档,记得包含请求示例、响应格式、错误码..."
Claude: "好的" # ✅ 这次做得很好
[下次]
你: "再生成一份 API 文档"
Claude: [生成的文档] # ❌ 这次忘记了错误码部分这些问题的根源是:每次对话都是全新的开始,Claude 无法记住你的领域知识、偏好和工作流程。
💡 Skills 系统的价值
Skills 就是解决这个问题的方案——它让你能够:
- 📦 封装领域知识: 把你反复向 Claude 解释的专业知识打包成 Skill
- 🔄 自动加载: 当任务相关时,Skill 自动激活,无需重复说明
- ♻️ 持续复用: 创建一次,跨所有对话自动使用
- 🎯 专业能力: 让 Claude 从通用助手进化为领域专家
本文核心内容:
- Skills 的核心概念与工作原理
- 渐进式披露架构:三级加载机制
- 创建自定义 Skills:从入门到精通
- 最佳实践:简洁、结构化、可验证
- 实战案例:PDF 处理、BigQuery 分析、代码审查
- 评估与迭代:如何持续优化 Skills
"把你反复向 Claude 解释的偏好、流程、领域知识打包成 Skills,让 AI 成为你的领域专家"
一、什么是 Skills?
1.1 核心概念
Agent Skills(智能体技能)是一种模块化的能力扩展系统,它为 Claude 提供了:
- 领域专业知识: 如 PDF 处理技巧、数据库 schema、业务规则
- 工作流程: 如代码审查流程、文档生成流程、数据分析流程
- 最佳实践: 如命名规范、代码风格、错误处理模式
1.2 Skills vs 普通 Prompt
| 维度 | 普通 Prompt | Skills |
|---|---|---|
| 作用范围 | 单次对话 | 跨所有相关对话 |
| 加载方式 | 每次手动提供 | 相关任务时自动加载 |
| 上下文占用 | 每次都占用 | 按需加载,未使用时零占用 |
| 知识管理 | 分散在多次对话中 | 集中管理,持续优化 |
| 一致性 | 依赖人工记忆 | 标准化,确保一致 |
类比理解:
- 普通 Prompt 像是每次都要"现场培训"新员工
- Skills 像是给员工提供"岗位手册",需要时自己查阅
1.3 Skills 遵循开放标准
Claude Code Skills 基于 Agent Skills 开放标准,这意味着:
- ✅ 标准化格式,跨 AI 工具兼容
- ✅ 社区生态,可以使用他人创建的 Skills
- ✅ 长期支持,不会因产品升级而失效
Claude Code 在标准基础上扩展了:
- 🔧 调用控制机制
- 🤖 子代理执行能力
- 📥 动态上下文注入
二、Skills 工作原理:渐进式披露架构
2.1 为什么需要渐进式披露?
问题:如果把所有 Skills 的详细内容都加载到上下文中会怎样?
假设你有 10 个 Skills,每个包含 5000 tokens 的详细指导...
总共: 50,000 tokens
但你可能只需要使用其中 1-2 个 Skill!
浪费: 40,000+ tokens(80% 的上下文窗口!)解决方案:渐进式披露——只加载需要的内容,按需展开详细信息。
2.2 三级加载机制
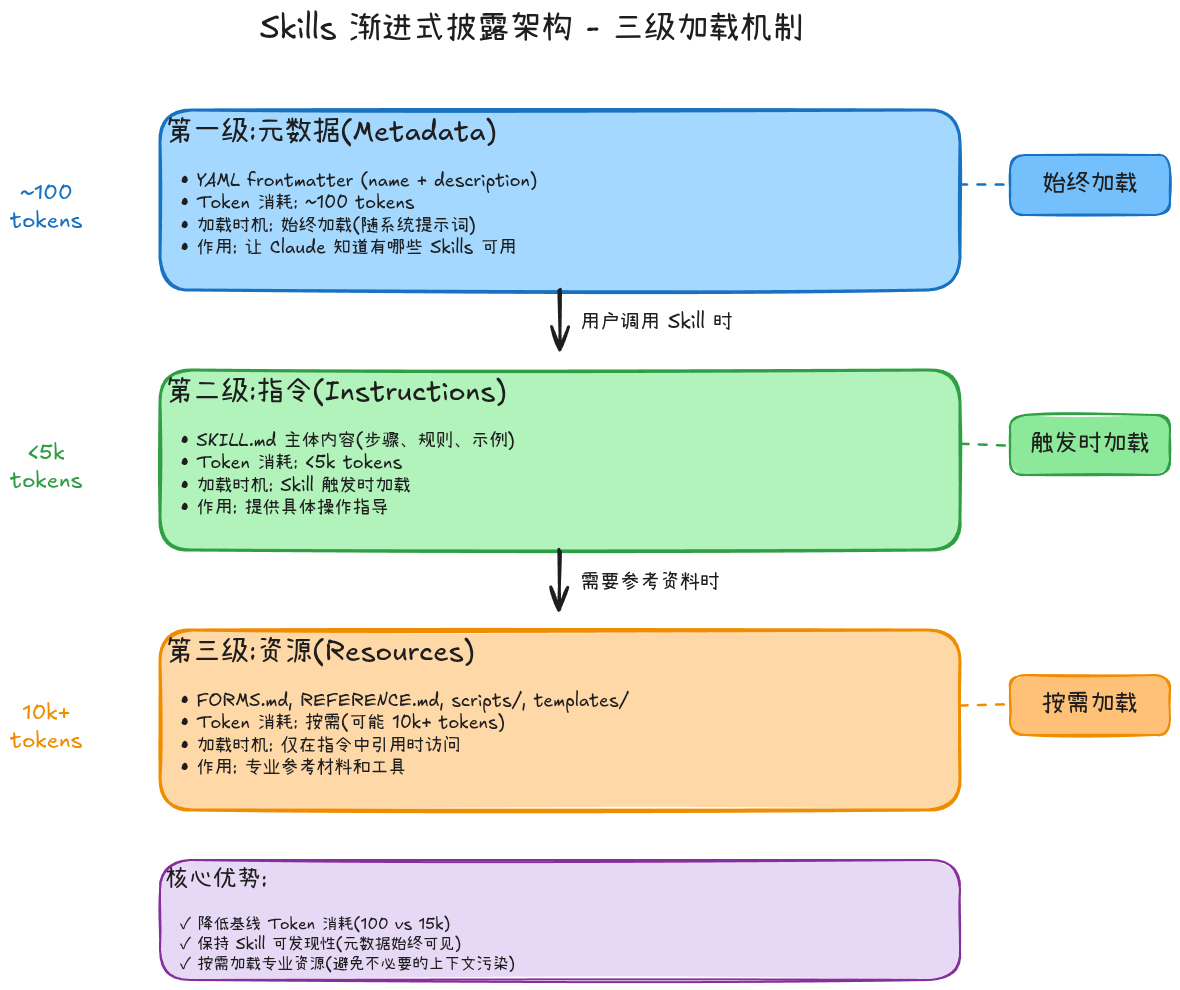
第一级:元数据(Metadata)- 始终加载
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs, forms,
or document extraction.
---- 加载时机: Claude 启动时
- Token 消耗: 每个 Skill 约 100 tokens
- 作用: 让 Claude 知道有哪些 Skills 可用,以及何时触发
关键字段解析:
name: Skill 标识符(小写字母、数字、连字符)description: 功能说明 + 触发场景(最重要的字段!)
⚠️ 重要: description 是 Skill 触发的关键。Claude 根据用户请求与 description 的匹配度决定是否加载该 Skill。
第二级:指令(Instructions)- 触发时加载
# PDF Processing
## Quick start
Use pdfplumber to extract text from PDFs:
\`\`\`python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
text = pdf.pages[0].extract_text()
\`\`\`
For advanced form filling, see [FORMS.md](FORMS.md).- 加载时机: 当用户请求匹配 Skill 描述时
- Token 消耗: 通常少于 5k tokens
- 作用: 提供具体的操作指导和工作流程
第三级:资源和代码(Resources & Code)- 按需访问
pdf-skill/
├── SKILL.md # 主指令文件(第二级)
├── FORMS.md # 表单填写指南(按需读取)
├── REFERENCE.md # 详细 API 参考(按需读取)
└── scripts/
└── fill_form.py # 工具脚本(执行时不加载代码)- 加载时机: 仅当 SKILL.md 中引用时
- Token 消耗: 脚本执行时只有输出占用 tokens
- 作用: 提供专业参考材料和可执行工具
2.3 实例演示:从触发到加载
场景: 用户请求"帮我提取 PDF 中的文本"
┌─────────────────────────────────────────┐
│ 步骤 1: Claude 检查所有 Skill 的元数据 │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 匹配到 pdf-processing Skill │
│ description 包含 "Extract text from PDF"│
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 步骤 2: 加载 SKILL.md 的指令内容 │
│ (~3k tokens) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 步骤 3: Claude 发现需要表单填写 │
│ 读取 FORMS.md (~2k tokens) │
└─────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 总 Token 消耗: 约 5k tokens │
│ 其他 9 个 Skills: 0 tokens(未加载) │
└─────────────────────────────────────────┘对比无渐进式披露:
❌ 传统方式: 10 个 Skills × 5k = 50k tokens
✅ 渐进式披露: 只加载 1 个 Skill = 5k tokens
节省: 45k tokens (90% 的上下文!)三、Skills 的文件结构
3.1 最小化 Skill
最简单的 Skill 只需要一个文件:
my-skill/
└── SKILL.md # 唯一必需的文件SKILL.md 示例:
---
name: code-review-checklist
description: Provides a code review checklist for pull requests. Use when reviewing code or when the user asks for code review guidelines.
---
# Code Review Checklist
When reviewing code, check:
1. **Functionality**: Does the code do what it's supposed to?
2. **Readability**: Is the code easy to understand?
3. **Tests**: Are there appropriate tests?
4. **Performance**: Are there any obvious performance issues?
5. **Security**: Are there any security vulnerabilities?
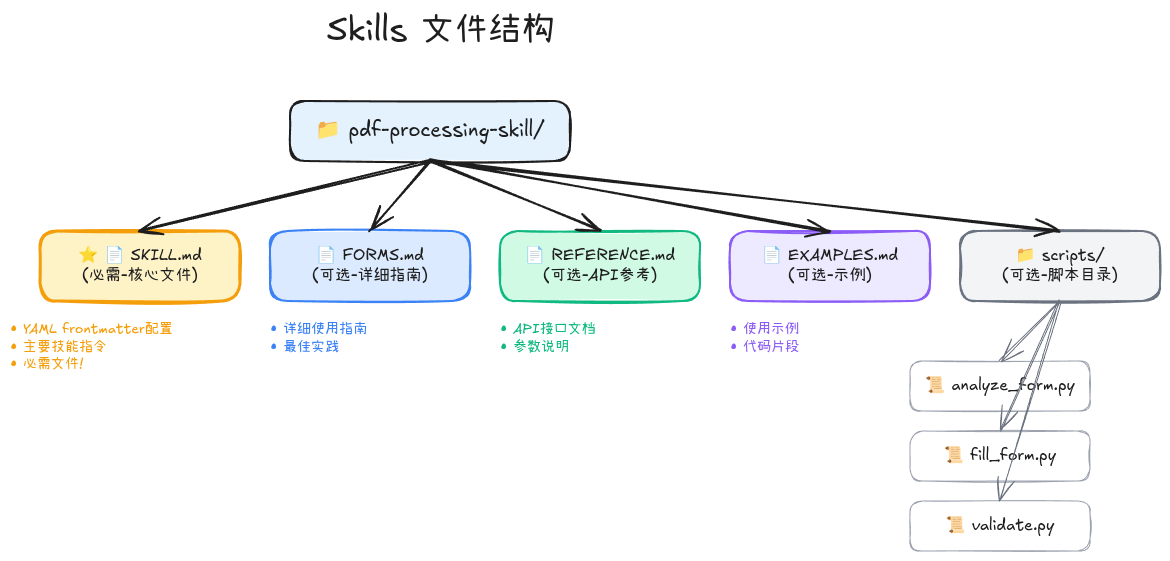
For each item, provide specific feedback with examples.3.2 完整 Skill 结构
对于复杂的 Skills,可以组织成多文件结构:
pdf-processing-skill/
├── SKILL.md # 核心指令(必需)
├── FORMS.md # 表单填写详细指南
├── REFERENCE.md # PDF 库 API 参考
├── EXAMPLES.md # 常见用例示例
└── scripts/
├── analyze_form.py # 分析表单工具
├── fill_form.py # 填写表单工具
└── validate.py # 验证输出工具3.3 YAML Frontmatter 规范
必填字段:
---
name: skill-name # 必填
description: Skill description # 必填
---字段要求:
| 字段 | 要求 | 示例 |
|---|---|---|
| name | 小写字母、数字、连字符 最多 64 字符 禁止 "anthropic"、"claude" | pdf-processingbigquery-analyticscode-reviewer |
| description | 非空 最多 1024 字符 包含功能 + 触发场景 第三人称描述 | Extract text from PDFs. Use when...Analyze BigQuery data. Use when... |
命名规范:
✅ 推荐: 动名词形式(Gerund Form)
processing-pdfs
analyzing-spreadsheets
reviewing-code
managing-databases❌ 避免: 过于模糊
helper # 太模糊
utils # 不知道干什么
tool # 功能不明确3.4 Description 字段的重要性
⚠️ 警告: description 是 Skill 触发的关键,必须用第三人称!
为什么必须第三人称?
description 会被注入到系统提示中,视角不一致会导致困惑:
系统提示: "You are Claude, an AI assistant..."
Skill description: "I can help you process PDFs" # ❌ 第一人称,视角冲突!正确示例:
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
Use when working with PDF files or when the user mentions PDFs, forms,
or document extraction.
---不正确示例:
❌ description: I can help you process Excel files # 第一人称
❌ description: You can use this to process Excel # 第二人称
❌ description: Helps with documents # 过于模糊编写技巧:
- 明确功能: 说清楚 Skill 能做什么
- 包含关键词: 用户可能使用的术语(PDF、Excel、BigQuery 等)
- 触发场景: 明确何时使用("Use when...")
- 简洁精准: 1-2 句话说清楚
四、创建你的第一个 Skill
4.1 确定需求
问题导向:
问自己:
- 我反复向 Claude 解释什么内容?
- 哪些领域知识 Claude 不太了解?
- 哪些工作流程需要标准化?
示例场景:
场景 1: BigQuery 数据分析
- ❌ 每次都要说明表结构
- ❌ 每次都要强调"排除测试账户"
- ❌ 每次都要说明查询模式
- ✅ 创建一个 BigQuery Skill!
场景 2: 公司文档规范
- ❌ 每次都要说明文档模板
- ❌ 每次都要强调格式要求
- ❌ 每次都要纠正不符合规范的部分
- ✅ 创建一个文档规范 Skill!
4.2 编写 SKILL.md
步骤 1: 创建目录和文件
mkdir my-bigquery-skill
cd my-bigquery-skill
touch SKILL.md步骤 2: 编写 YAML Frontmatter
---
name: bigquery-analytics
description: Analyze BigQuery data from the user_metrics and sales tables. Use when the user asks about data analysis, metrics, or BigQuery queries. Always exclude test accounts and apply standard
date filters.
---步骤 3: 编写核心指令
# BigQuery Analytics
## Database Schema
### user_metrics table
- user_id (STRING): Unique user identifier
- event_date (DATE): Event date
- metrics_value (FLOAT): Metric value
- account_type (STRING): "production" or "test"
### sales table
- order_id (STRING): Order identifier
- user_id (STRING): User ID (foreign key to user_metrics)
- amount (FLOAT): Order amount
- order_date (DATE): Order date
## Standard Filtering Rules
**Always apply these filters:**
1. Exclude test accounts: `WHERE account_type = 'production'`
2. Date range: Default to last 30 days unless specified
3. Remove null values: `WHERE metrics_value IS NOT NULL`
## Query Patterns
### Pattern 1: User activity analysis
\`\`\`sql
SELECT
event_date,
COUNT(DISTINCT user_id) as active_users,
AVG(metrics_value) as avg_metric
FROM user_metrics
WHERE account_type = 'production'
AND event_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
GROUP BY event_date
ORDER BY event_date;
\`\`\`
### Pattern 2: Sales analysis
\`\`\`sql
SELECT
DATE_TRUNC(order_date, MONTH) as month,
COUNT(*) as order_count,
SUM(amount) as total_revenue
FROM sales s
JOIN user_metrics u ON s.user_id = u.user_id
WHERE u.account_type = 'production'
GROUP BY month
ORDER BY month;
\`\`\`
## Important Notes
- **Performance**: Always use partitioned date fields in WHERE clause
- **Costs**: Preview query cost before running on large datasets
- **Timezone**: All dates are in UTC五、核心最佳实践
5.1 简洁为王(Conciseness is Key)
核心原则: 上下文窗口是公共资源,你的 Skill 要与系统提示、对话历史、其他 Skills 共享。
✅ 好的示例(约 50 tokens)
## Extract PDF Text
Use pdfplumber for text extraction:
\`\`\`python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
\`\`\`❌ 糟糕的示例(约 150 tokens)
## Extract PDF Text
PDF(便携式文档格式)是一种常见的文件格式,包含文本、图像等内容。
要从 PDF 中提取文本,你需要使用一个库。有很多 PDF 处理库可用,
但我们推荐 pdfplumber,因为它易于使用且能处理大多数情况。
首先,你需要使用 pip 安装它。然后你可以使用下面的代码...为什么简洁版更好?
- ✅ 假设 Claude 已经知道 PDF 是什么
- ✅ 假设 Claude 知道库的工作原理
- ✅ 直接提供关键信息:用什么库、怎么用
- ✅ 节省 100 tokens,留给其他 Skills 使用
⚠️ 记住: 不要低估 Claude 的智能!它是通用 AI,不需要你解释基础概念。
5.2 设置适当的自由度
根据任务的脆弱性和可变性,选择合适的指导程度。
🌟 高自由度(基于文本的指令)
适用场景:
- 多种方法都可行
- 决策依赖上下文
- 启发式方法指导
示例:代码审查流程
## Code Review Process
1. Analyze code structure and organization
2. Check for potential bugs or edge cases
3. Suggest improvements for readability and maintainability
4. Verify compliance with project standards特点: 给出大方向,信任 Claude 根据具体情况调整。
🎯 中等自由度(伪代码或带参数的脚本)
适用场景:
- 存在首选模式
- 允许一定变化
- 配置影响行为
示例:生成报告
## Generate Report
Use this template and customize as needed:
\`\`\`python
def generate_report(data, format="markdown", include_charts=True):
# Process data
# Generate output in specified format
# Optionally include visualizations
\`\`\`特点: 提供模板和参数,允许根据需求调整。
🔒 低自由度(特定脚本,少量或无参数)
适用场景:
- 操作易错且脆弱
- 一致性至关重要
- 必须遵循特定顺序
示例:数据库迁移
## Database Migration
Execute this script strictly:
\`\`\`bash
python scripts/migrate.py --verify --backup
\`\`\`
Do not modify the command or add extra parameters.特点: 精确指令,不允许偏离。
🌉 类比理解
把 Claude 想象成在不同地形上探索的机器人:
- 悬崖边的窄桥(低自由度): 只有一条安全路径 → 提供详细护栏和精确指令
- 丘陵地带(中等自由度): 几条推荐路径 → 提供地图和指南针
- 无障碍的开阔草地(高自由度): 多条路径都能成功 → 给出大致方向,信任 Claude 找到最佳路线
5.3 渐进式披露模式
模式 1:高层指南 + 引用
结构:
SKILL.md (简要指南)
↓ 引用
[FORMS.md] [REFERENCE.md] [EXAMPLES.md]示例:
# PDF Processing
## Quick Start
Use pdfplumber to extract text:
\`\`\`python
import pdfplumber
with pdfplumber.open("file.pdf") as pdf:
text = pdf.pages[0].extract_text()
\`\`\`
## Advanced Features
**Form Filling**: See [FORMS.md](FORMS.md) for complete guide
**API Reference**: See [REFERENCE.md](REFERENCE.md) for all methods
**Examples**: See [EXAMPLES.md](EXAMPLES.md) for common patterns优势:
- Claude 只在需要时才读取 FORMS.md、REFERENCE.md 或 EXAMPLES.md
- 未使用的文件 = 0 tokens 消耗
模式 2:按领域组织
适用场景: 多领域的 Skills,避免加载无关上下文
结构:
bigquery-skill/
├── SKILL.md # 概述和导航
└── reference/
├── finance.md # 财务指标
├── sales.md # 销售数据
├── product.md # 产品分析
└── marketing.md # 营销活动示例:
# BigQuery Analytics
## Domain Reference
- **Finance Metrics**: See [reference/finance.md](reference/finance.md)
- **Sales Data**: See [reference/sales.md](reference/sales.md)
- **Product Analytics**: See [reference/product.md](reference/product.md)
- **Marketing Campaigns**: See [reference/marketing.md](reference/marketing.md)优势:
- 用户询问销售指标时,只读取 sales.md
- finance.md 和其他文件保持在文件系统中,消耗 0 tokens
模式 3:条件细节
# DOCX Processing
## Create Documents
Use docx-js to create new documents. See [DOCX-JS.md](DOCX-JS.md).
## Edit Documents
For simple edits, modify XML directly.
**Track Changes**: See [REDLINING.md](REDLINING.md)
**OOXML Details**: See [OOXML.md](OOXML.md)优势:
- 常见操作(创建文档)在主文件中
- 高级功能(追踪更改)按需引用
💡 重要: 保持引用层级为一级深度。避免 SKILL.md → advanced.md → details.md 这样的深层嵌套。
5.4 工作流和反馈循环
复杂任务的工作流模式
为多步骤任务提供清晰的检查清单:
## PDF Form Filling Workflow
Copy this checklist and track progress:
\`\`\`
Task Progress:
- [ ] Step 1: Analyze form (run analyze_form.py)
- [ ] Step 2: Create field mapping (edit fields.json)
- [ ] Step 3: Validate mapping (run validate_fields.py)
- [ ] Step 4: Fill form (run fill_form.py)
- [ ] Step 5: Verify output (run verify_output.py)
\`\`\`
**Step 1: Analyze Form**
Run: `python scripts/analyze_form.py input.pdf`
This extracts form fields and their locations, saving to `fields.json`.
**Step 2: Create Field Mapping**
Edit `fields.json` to add values for each field.
**Step 3: Validate Mapping**
Run: `python scripts/validate_fields.py fields.json`
Fix any validation errors before proceeding.
**Step 4: Fill Form**
Run: `python scripts/fill_form.py input.pdf fields.json output.pdf`
**Step 5: Verify Output**
Run: `python scripts/verify_output.py output.pdf`
If validation fails, return to Step 2.实现反馈循环
常见模式: 运行验证器 → 修复错误 → 重复
这种模式极大提高输出质量。
示例:文档编辑流程
## Document Editing Flow
1. Make edits to `word/document.xml`
2. **Validate immediately**: `python ooxml/scripts/validate.py unpacked_dir/`
3. If validation fails:
- Review error messages carefully
- Fix issues in XML
- Run validation again
4. **Only proceed when validation passes**
5. Repack: `python ooxml/scripts/pack.py unpacked_dir/ output.docx`
6. Test output document为什么反馈循环重要?
- ✅ 及早发现错误(在应用更改前)
- ✅ 机器可验证(脚本提供客观验证)
- ✅ 可逆计划(Claude 可以迭代而不破坏原始文件)
- ✅ 清晰调试(错误消息指向具体问题)
5.5 内容指南
避免时间敏感信息
❌ 糟糕示例(会过时):
如果你在 2025 年 8 月之前做这件事,使用旧 API。
2025 年 8 月之后,使用新 API。✅ 好的示例(使用"旧模式"部分):
## Current Method
Use v2 API endpoint: `api.example.com/v2/messages`
## Legacy Patterns
<details>
<summary>Legacy v1 API (deprecated 2025-08)</summary>
v1 API uses: `api.example.com/v1/messages`
This endpoint is no longer supported.
</details>使用一致的术语
在整个 Skill 中选择一个术语并坚持使用:
✅ 一致性好:
- 始终使用 "API endpoint"
- 始终使用 "field"
- 始终使用 "extract"
❌ 不一致:
- 混用 "API endpoint"、"URL"、"API route"、"path"
- 混用 "field"、"box"、"element"、"control"
- 混用 "extract"、"pull"、"get"、"retrieve"
六、高级技巧
6.1 包含可执行代码的 Skills
解决问题,而非推卸责任
编写 Skills 脚本时,显式处理错误情况,而非推卸给 Claude。
✅ 好的示例:显式处理错误
def process_file(path):
"""处理文件,如果不存在则创建。"""
try:
with open(path) as f:
return f.read()
except FileNotFoundError:
# 创建默认内容而非失败
print(f"文件 {path} 未找到,创建默认文件")
with open(path, 'w') as f:
f.write('')
return ''
except PermissionError:
# 提供替代方案而非失败
print(f"无法访问 {path},使用默认值")
return ''❌ 糟糕示例:推卸给 Claude
def process_file(path):
# 直接失败,让 Claude 自己想办法
return open(path).read()提供工具脚本
即使 Claude 可以编写脚本,预制脚本也有优势:
工具脚本的好处:
- 比生成代码更可靠
- 节省 tokens(无需在上下文中包含代码)
- 节省时间(无需代码生成)
- 确保使用的一致性
示例:
## Tool Scripts
**analyze_form.py**: Extract all form fields from PDF
\`\`\`bash
python scripts/analyze_form.py input.pdf > fields.json
\`\`\`
Output format:
\`\`\`json
{
"field_name": {"type": "text", "x": 100, "y": 200},
"signature": {"type": "sig", "x": 150, "y": 500}
}
\`\`\`
**validate_boxes.py**: Check for boundary box overlaps
\`\`\`bash
python scripts/validate_boxes.py fields.json
# Returns: "OK" or lists conflicts
\`\`\`
**fill_form.py**: Apply field values to PDF
\`\`\`bash
python scripts/fill_form.py input.pdf fields.json output.pdf
\`\`\`💡 重要区分: 在指令中明确说明 Claude 应该:
- 执行脚本(最常见): "运行 analyze_form.py 以提取字段"
- 读取作为参考(用于复杂逻辑): "参见 analyze_form.py 了解字段提取算法"
6.2 创建可验证的中间输出
当 Claude 执行复杂、开放式任务时,可能会出错。"计划-验证-执行"模式通过让 Claude 首先创建结构化格式的计划,然后在执行前用脚本验证该计划,从而及早发现错误。
示例场景
要求: Claude 根据电子表格更新 PDF 中的 50 个表单字段。
没有验证:Claude 可能:
- ❌ 引用不存在的字段
- ❌ 创建冲突的值
- ❌ 遗漏必填字段
- ❌ 错误应用更新
有验证:工作流变为:
分析 → 创建计划文件 → 验证计划 → 执行 → 验证输出添加一个中间 changes.json 文件,在应用更改前进行验证。
实现示例
## Bulk Form Update Workflow
**Step 1: Analyze**
- Extract current form fields
- Save to `current_fields.json`
**Step 2: Create Change Plan**
- Based on spreadsheet, create `changes.json`:
\`\`\`json
{
"field_updates": [
{"field": "customer_name", "value": "John Doe"},
{"field": "order_total", "value": "1250.00"}
]
}
\`\`\`
**Step 3: Validate Plan**
- Run: `python scripts/validate_changes.py changes.json`
- Script checks:
- All referenced fields exist
- Values are in correct format
- No conflicts
- **Only proceed if validation passes**
**Step 4: Execute**
- Apply changes: `python scripts/apply_changes.py changes.json`
**Step 5: Verify Output**
- Run: `python scripts/verify_output.py output.pdf`为什么此模式有效
- 及早发现错误: 在应用更改前验证发现问题
- 机器可验证: 脚本提供客观验证
- 可逆计划: Claude 可以在不触及原始文件的情况下迭代计划
- 清晰调试: 错误消息指向具体问题
使用时机
- 批量操作
- 破坏性更改
- 复杂验证规则
- 高风险操作
💡 实现技巧: 让验证脚本输出详细的错误消息:
❌ 模糊: "Validation failed"
✅ 清晰: "Field 'signature_date' not found. Available fields: customer_name, order_total, signature_date_signed"这帮助 Claude 快速修复问题。
6.3 MCP 工具引用
如果你的 Skill 使用 MCP(Model Context Protocol)工具,始终使用完全限定的工具名称以避免"工具未找到"错误。
格式
ServerName:tool_name示例
## Query Database Schema
Use the BigQuery:bigquery_schema tool to retrieve table schema.
\`\`\`
Use tool: BigQuery:bigquery_schema
Parameters: {"table": "user_metrics"}
\`\`\`
## Create GitHub Issue
Use the GitHub:create_issue tool to create an issue.
\`\`\`
Use tool: GitHub:create_issue
Parameters: {"title": "Bug report", "body": "Description"}
\`\`\`说明
BigQuery和GitHub是 MCP 服务器名称bigquery_schema和create_issue是这些服务器中的工具名称
没有服务器前缀,Claude 可能无法找到工具,特别是当有多个 MCP 服务器可用时。
七、常见反模式
❌ 反模式 1:Windows 风格路径
问题:使用反斜杠 \ 作为路径分隔符
❌ 错误:
参见 scripts\helper.py
参见 reference\guide.md✅ 正确:
参见 scripts/helper.py
参见 reference/guide.md原因:
- Unix 风格路径跨所有平台工作
- Windows 风格路径在 Unix 系统上会导致错误
❌ 反模式 2:提供太多选项
问题:列出所有可能的方法,让 Claude 困惑
❌ 错误:
你可以使用 pypdf,或 pdfplumber,或 PyMuPDF,或 pdf2image,
或 pikepdf,或 PyPDF2,或 pdfrw,或 pdfminer...✅ 正确:
使用 pdfplumber 进行文本提取:
\`\`\`python
import pdfplumber
\`\`\`
对于需要 OCR 的扫描 PDF,改用 pdf2image 配合 pytesseract。原则:
- 提供默认推荐方法
- 只在特殊情况下提供替代方案
- 不要列出所有可能性
❌ 反模式 3:深层嵌套引用
问题:引用链太长,Claude 难以跟踪
❌ 错误:
SKILL.md → advanced.md → details.md → examples.md✅ 正确:
SKILL.md
↓ 直接引用
[ADVANCED.md] [DETAILS.md] [EXAMPLES.md]原则:
- 保持从 SKILL.md 的引用为一级深度
- 所有引用文件应直接从 SKILL.md 链接
❌ 反模式 4:过度解释基础概念
问题:解释 Claude 已经知道的内容
❌ 错误:
PDF(Portable Document Format,便携式文档格式)是 Adobe 公司
开发的一种文件格式,可以在不同操作系统上保持一致的显示效果。
PDF 文件包含文本、图像、矢量图形等多种内容类型...✅ 正确:
使用 pdfplumber 提取 PDF 文本。原则:
- 假设 Claude 的智能
- 只提供 Claude 不知道的领域特定知识
❌ 反模式 5:第一人称描述
问题:使用"我"、"你"等人称
❌ 错误:
description: I can help you process Excel files and generate reports.✅ 正确:
description: Process Excel files and generate reports. Use when working with spreadsheets or when the user mentions Excel, CSV, or data analysis.原因:
- description 被注入系统提示
- 第一人称会导致视角冲突
八、总结与行动
8.1 核心收益
通过 Skills 系统,你可以:
- ⏱️ 节省时间: 不用每次重复说明领域知识
- ✅ 保证质量: 标准化流程,减少错误
- 📚 积累知识: 把最佳实践封装成 Skills,团队共享
- 🚀 提升专业性: 让 Claude 从通用助手进化为领域专家
- 🔧 持续优化: 基于使用反馈不断改进 Skills
8.2 Skills 与其他功能的关系
| 功能 | 作用 | 与 Skills 的关系 |
|---|---|---|
| Agent | 处理复杂、多步骤任务 | Skills 为 Agent 提供领域知识 |
| MCP | 连接外部工具和数据源 | Skills 可以引用 MCP 工具 |
| claude.md | 项目级配置和规范 | Skills 是跨项目的能力扩展 |
| Hook | 事件触发的自动化 | Hook 可以在特定时机加载 Skills |
8.3 实践建议
对于个人开发者:
- 从一个简单的 Skill 开始(如代码审查清单)
- 识别自己反复解释的内容
- 逐步添加更多 Skills
- 持续优化基于实际使用
对于团队:
- 建立团队 Skills 仓库
- 统一 Skills 开发规范
- 定期分享优秀 Skills
- 建立 Skills 评审机制
对于技术 Leader:
- 推广 Skills 使用文化
- 组织 Skills 开发培训
- 激励团队贡献 Skills
- 建立 Skills 质量标准
8.4 未来展望
Skills 系统的发展方向:
- 可视化 Skill Builder: 通过图形界面创建 Skills
- Skill 市场: 官方 Skills 商店,一键安装分享
- AI 生成 Skills: 描述需求,AI 自动生成 Skills
- Skill 编排: 多个 Skills 组合成工作流
- 实时协作: 团队实时共享和更新 Skills
"把你反复向 Claude 解释的偏好、流程、领域知识打包成 Skills,让 AI 成为你的领域专家"
实用资源
🔗 相关文章:
如果这篇文章对你有帮助,欢迎点赞、收藏、分享!有任何问题或建议,欢迎在评论区留言讨论。让我们一起学习,一起成长!
也欢迎访问我的个人主页发现更多宝藏资源