引言
如果你曾经好奇Android应用是如何跨进程调用系统服务的,或者为什么Binder被称为Android的"神经系统",那么这篇文章就是为你准备的。
作为Android系统最核心的IPC(进程间通信)机制,Binder不仅是应用与系统服务交互的桥梁,更是整个Android生态的基石。从应用启动、四大组件通信,到系统服务调用,处处都有Binder的身影。掌握Binder,你就掌握了理解Android系统运行机制的钥匙。
本文将深入Android 15源码,从内核驱动层面剖析Binder的设计哲学、实现原理和工作机制。我们不仅要看代码,更要理解背后的"为什么"——为什么Android要设计一个全新的IPC机制?它相比传统Linux IPC有什么优势?
你将学到:
- Binder的设计哲学与架构全景
- Binder驱动的内核实现细节
- 一次拷贝的内存映射机制
- Binder协议结构与命令交互
- 从源码角度理解Binder工作流程
为什么需要Binder?
在深入技术细节之前,我们先回答一个本质问题:Android为什么要重新发明轮子,而不是用Linux已有的IPC机制?
传统Linux IPC的局限
Linux提供了多种IPC机制:管道(Pipe)、消息队列(Message Queue)、共享内存(Shared Memory)、Socket等。它们都能实现进程间通信,但在移动场景下都有明显的短板:
| IPC机制 | 数据拷贝次数 | 安全性 | 面向对象 | 适用场景 |
|---|---|---|---|---|
| 管道/消息队列 | 2次 | 弱 | 否 | 单向数据流 |
| Socket | 2次 | 中 | 否 | 网络通信 |
| 共享内存 | 0次 | 无 | 否 | 需配合其他机制 |
| Binder | 1次 | 强 | 是 | 移动系统服务 |
性能问题:传统IPC通常需要2次数据拷贝(用户空间→内核空间→用户空间),在高频调用场景下性能损耗明显。
安全问题:传统IPC缺乏完善的身份认证机制。Socket虽然可以通过UID/PID验证,但需要额外编码。移动系统需要更严格的权限控制。
面向对象:Android是基于Java的面向对象系统,需要能直接传递对象引用、支持接口调用的IPC机制。
Binder的设计目标
Binder的设计充分考虑了移动系统的特点:
- 高性能:一次拷贝,通过内存映射减少数据传输开销
- 强安全:内核级身份验证,支持UID/PID/SELINUX三重防护
- 面向对象:天然支持对象引用、接口调用、生命周期管理
- 稳定性:支持死亡通知、引用计数,服务异常能及时感知
💡 有趣的历史: Binder最初来自OpenBinder项目,由Be Inc.(后被Palm收购)开发。Google收购Android后,将其移植到Linux内核,成为Android的核心组件。
Binder架构全景
在深入驱动实现前,我们先从整体上理解Binder的分层架构。
四层架构
Binder采用经典的C/S(Client-Server)架构,由四个主要部分组成:
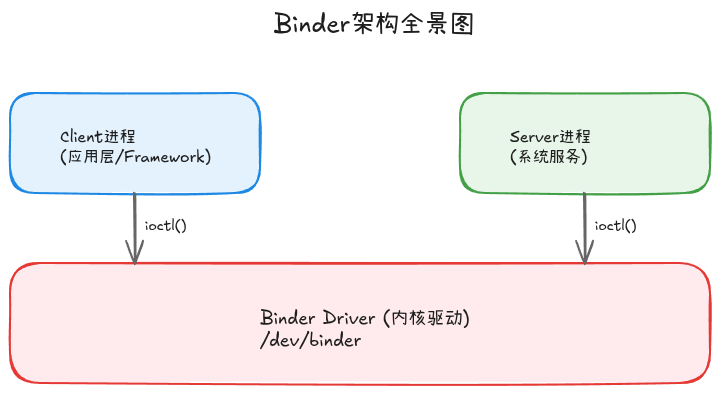
图1: Binder三层架构 - Client和Server通过Binder Driver进行IPC通信
用户空间:
- BpBinder(Proxy Binder):客户端代理,持有远程Binder的引用(handle)
- BBinder(Base Binder):服务端实体,真正提供服务的对象
内核空间:
- Binder Driver:内核驱动,管理所有Binder通信的中枢
核心概念
理解Binder必须掌握几个核心概念:
1. Binder实体与引用
- Binder实体(binder_node):服务端的真实对象,存在于Server进程
- Binder引用(binder_ref):客户端持有的远程对象引用,通过handle标识
这类似于指针和句柄的关系:Server持有对象的实际地址,Client持有一个整数句柄,通过驱动映射到真实对象。
2. 进程与线程上下文
- binder_proc:每个使用Binder的进程在驱动中都有一个binder_proc结构,维护该进程的所有Binder状态
- binder_thread:每个参与Binder通信的线程在驱动中都有一个binder_thread结构,管理线程的工作队列
3. 数据缓冲区
- binder_buffer:驱动为每次通信分配的数据缓冲区,存储传输的数据
Binder驱动初始化
让我们从源码角度看Binder驱动是如何初始化的。
ProcessState:进程单例
每个使用Binder的进程都会创建一个ProcessState单例对象,负责打开Binder驱动并进行初始化。
// ProcessState.cpp (Android 15)
sp<ProcessState> ProcessState::self() {
return init(kDefaultDriver, false);
}
sp<ProcessState> ProcessState::init(const char* driver, bool requireDefault) {
// ...
std::call_once(gProcessOnce, [&](){
if (access(driver, R_OK) == -1) {
ALOGE("Binder driver %s is unavailable.", driver);
driver = "/dev/binder";
}
// 创建全局单例
gProcess = sp<ProcessState>::make(driver);
});
return gProcess;
}打开设备节点
ProcessState构造时会打开/dev/binder设备节点:
// ProcessState.cpp
ProcessState::ProcessState(const char* driver)
: mDriverName(String8(driver))
, mDriverFD(-1) // Binder驱动文件描述符
, mVMStart(MAP_FAILED) // mmap映射的起始地址
, mThreadCountLock(PTHREAD_MUTEX_INITIALIZER)
, mThreadCountDecrement(PTHREAD_COND_INITIALIZER)
, mExecutingThreadsCount(0)
, mWaitingForThreads(0)
, mMaxThreads(DEFAULT_MAX_BINDER_THREADS) // 默认15个线程
, mStarvationStartTimeMs(0)
, mForked(false)
, mThreadPoolStarted(false)
, mThreadPoolSeq(1)
, mCallRestriction(CallRestriction::NONE) {
// 打开Binder驱动
mDriverFD = open(driver, O_RDWR | O_CLOEXEC);
if (mDriverFD >= 0) {
// 关键步骤:通过mmap映射内核缓冲区
mVMStart = mmap(nullptr, BINDER_VM_SIZE, // 默认 1MB - 8KB
PROT_READ, // 只读映射
MAP_PRIVATE | MAP_NORESERVE,
mDriverFD, 0);
if (mVMStart == MAP_FAILED) {
close(mDriverFD);
mDriverFD = -1;
}
}
}关键点解析:
- 设备节点:
/dev/binder是Binder驱动注册的字符设备 - 内存映射:通过
mmap将内核缓冲区映射到进程地址空间,这是实现一次拷贝的关键 - 映射大小:默认
(1MB - 8KB),对大多数场景足够 - 只读映射:用户空间只能读取,不能直接写入,保证安全性
BINDER_VM_SIZE的计算
// ProcessState.cpp
#define BINDER_VM_SIZE ((1 * 1024 * 1024) - sysconf(_SC_PAGE_SIZE) * 2)为什么要减去2个页面(通常是8KB)?
- 预留一些空间作为保护页(guard page)
- 避免越界访问导致的内存错误
- 典型值:
1MB - 8KB = 1,040,384 bytes
内存映射:一次拷贝的魔法
Binder最引以为傲的特性就是"一次拷贝",这是如何实现的?
传统IPC的两次拷贝
在传统IPC中,数据传输需要两次拷贝:
Client用户空间 ──copy1──> 内核空间 ──copy2──> Server用户空间每次copy都需要CPU参与,在传输大数据时性能损耗明显。
Binder的一次拷贝
Binder通过巧妙的内存映射设计,将拷贝次数减少到一次:
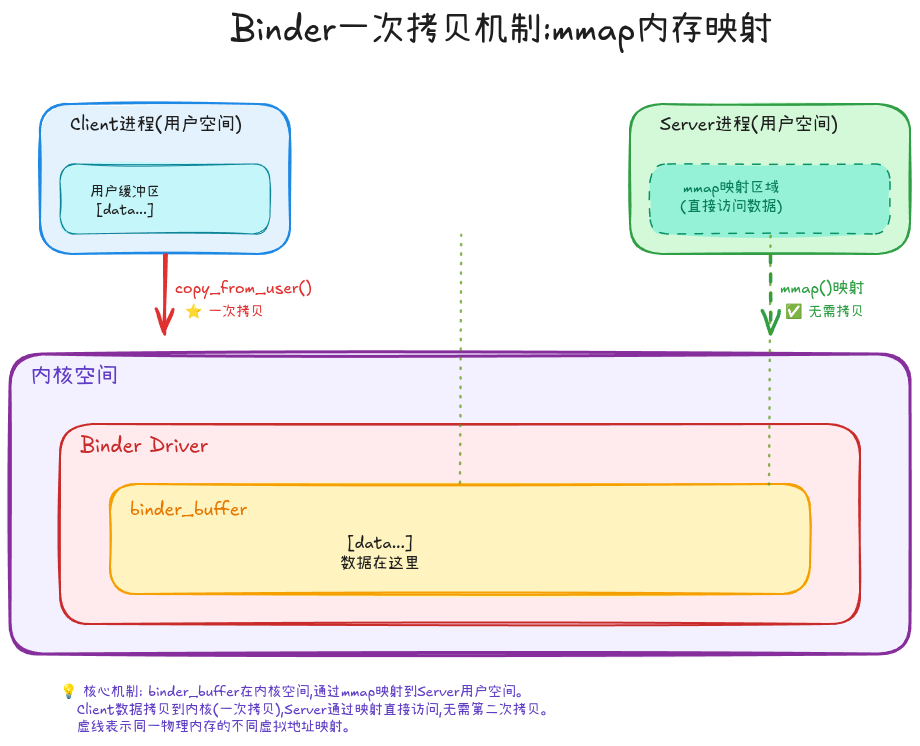
核心机制:
- Server进程启动时,通过
mmap将内核中的binder_buffer映射到自己的用户空间 - Client发送数据时,驱动通过
copy_from_user将数据从Client用户空间拷贝到内核的binder_buffer - 由于binder_buffer已经映射到Server用户空间,Server可以直接读取,无需第二次拷贝
🎯 关键洞察: 这里的映射是单向的——只有Server进程映射内核缓冲区,Client不映射。数据从Client→内核(一次拷贝),然后Server通过映射直接访问,总共一次拷贝。
mmap在驱动中的实现
当用户空间调用mmap时,会触发驱动的binder_mmap函数:
// 简化版的binder_mmap逻辑(基于Android 15)
static int binder_mmap(struct file *filp, struct vm_area_struct *vma) {
struct binder_proc *proc = filp->private_data;
// 计算映射大小
size_t size = vma->vm_end - vma->vm_start;
// 分配物理页面
proc->pages = kcalloc(proc->buffer_size / PAGE_SIZE,
sizeof(proc->pages[0]), GFP_KERNEL);
// 分配内核虚拟地址空间
proc->buffer = (void *)vm_map_ram(proc->pages,
proc->buffer_size / PAGE_SIZE,
-1);
// 建立用户空间到内核空间的映射
// 用户空间虚拟地址 <-> 物理页面 <-> 内核虚拟地址
for (page_addr = vma->vm_start; page_addr < vma->vm_end;
page_addr += PAGE_SIZE) {
page = &proc->pages[(page_addr - vma->vm_start) / PAGE_SIZE];
vm_insert_page(vma, page_addr, page);
}
return 0;
}映射建立流程:
- 分配物理内存页面
- 在内核空间建立虚拟地址映射
- 在用户空间建立虚拟地址映射
- 两者都指向同一批物理页面
这样,当驱动将数据写入内核虚拟地址时,用户空间映射的地址也能立即看到数据,无需额外拷贝。
Binder协议结构
Binder使用基于命令的通信协议,Client和Server通过发送命令与驱动交互。
BC/BR命令
Binder协议命令分为两类:
- BC_(Binder Command):用户空间发送给驱动的命令
- BR_(Binder Return):驱动返回给用户空间的命令
// IPCThreadState.cpp - Android 15
static const char* kCommandStrings[] = {
"BC_TRANSACTION", // 发起事务(调用远程方法)
"BC_REPLY", // 事务回复
"BC_ACQUIRE_RESULT", // 获取对象结果
"BC_FREE_BUFFER", // 释放缓冲区
"BC_INCREFS", // 增加弱引用
"BC_ACQUIRE", // 增加强引用
"BC_RELEASE", // 释放强引用
"BC_DECREFS", // 减少弱引用
"BC_REGISTER_LOOPER", // 注册线程池线程
"BC_ENTER_LOOPER", // 进入消息循环
"BC_EXIT_LOOPER", // 退出消息循环
// ... Android 15新增
"BC_REQUEST_FREEZE_NOTIFICATION", // 请求冻结通知
"BC_CLEAR_FREEZE_NOTIFICATION", // 清除冻结通知
};
static const char* kReturnStrings[] = {
"BR_ERROR", // 错误
"BR_OK", // 成功
"BR_TRANSACTION", // 接收到事务请求
"BR_REPLY", // 接收到事务回复
"BR_DEAD_REPLY", // 对方已死亡
"BR_TRANSACTION_COMPLETE", // 事务已完成
"BR_INCREFS", // 增加弱引用
"BR_ACQUIRE", // 增加强引用
"BR_RELEASE", // 释放强引用
"BR_DECREFS", // 减少弱引用
"BR_NOOP", // 空操作
"BR_SPAWN_LOOPER", // 建议创建新线程
"BR_DEAD_BINDER", // Binder对象已死亡
// ... Android 15新增
"BR_FROZEN_BINDER", // Binder被冻结
"BR_ONEWAY_SPAM_SUSPECT", // 单向调用垃圾检测
};核心数据结构
binder_transaction_data:描述一次Binder调用的数据
struct binder_transaction_data {
union {
size_t handle; // 目标Binder引用(Client使用)
void *ptr; // 目标Binder指针(Server使用)
} target;
void *cookie; // Server端私有数据
unsigned int code; // 调用的方法编号
unsigned int flags; // 标志位(同步/异步/单向)
#define TF_ONE_WAY 0x01 // 单向调用,不等待回复
#define TF_ACCEPT_FDS 0x10 // 接受文件描述符
pid_t sender_pid; // 发送方进程ID
uid_t sender_euid; // 发送方用户ID
size_t data_size; // 数据大小
size_t offsets_size; // 偏移数组大小(用于Binder对象)
union {
struct {
const void *buffer; // 数据缓冲区
const void *offsets; // Binder对象偏移数组
} ptr;
uint8_t buf[8];
} data;
};关键字段解析:
- target.handle:目标服务的句柄值,由驱动维护的引用ID
- code:要调用的方法编号,由AIDL生成器自动分配
- flags:标志位,最重要的是
TF_ONE_WAY(单向调用) - sender_pid/sender_euid:发送方身份,由驱动填充,无法伪造,这是Binder安全性的基础
- data.ptr.buffer:实际传输的数据
- data.ptr.offsets:数据中包含的Binder对象位置,驱动需要特殊处理
ioctl交互
用户空间通过ioctl系统调用与驱动交互:
// IPCThreadState.cpp
status_t IPCThreadState::talkWithDriver(bool doReceive) {
binder_write_read bwr;
// 准备写入数据
bwr.write_size = mOut.dataSize();
bwr.write_buffer = (uintptr_t)mOut.data();
// 准备读取数据
bwr.read_size = mIn.dataCapacity();
bwr.read_buffer = (uintptr_t)mIn.data();
// 核心:调用ioctl
status_t err = ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr);
// 处理返回结果
if (bwr.write_consumed > 0) {
mOut.remove(0, bwr.write_consumed);
}
if (bwr.read_consumed > 0) {
mIn.setDataSize(bwr.read_consumed);
}
return err;
}binder_write_read结构:
struct binder_write_read {
signed long write_size; // 要写入的字节数
signed long write_consumed; // 驱动已消费的字节数
unsigned long write_buffer; // 写缓冲区地址
signed long read_size; // 读缓冲区大小
signed long read_consumed; // 驱动已填充的字节数
unsigned long read_buffer; // 读缓冲区地址
};💡 设计巧思: 一次ioctl调用同时支持读和写,减少系统调用次数。驱动会先处理write_buffer中的命令,再填充read_buffer返回数据。
Binder通信流程
理解了基础概念后,让我们看一次完整的Binder调用是如何完成的。
发起调用(Client侧)
// BpBinder.cpp (Android 15)
status_t BpBinder::transact(uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags) {
// 检查Binder是否存活
if (mAlive) {
// 委托给IPCThreadState执行
status_t status = IPCThreadState::self()->transact(
mHandle, // 目标服务的handle
code, // 方法编号
data, // 参数数据
reply, // 回复数据
flags); // 标志位
if (status == DEAD_OBJECT) mAlive = 0;
return status;
}
return DEAD_OBJECT;
}// IPCThreadState.cpp
status_t IPCThreadState::transact(int32_t handle, uint32_t code,
const Parcel& data, Parcel* reply,
uint32_t flags) {
// 准备binder_transaction_data
binder_transaction_data tr;
tr.target.handle = handle;
tr.code = code;
tr.flags = flags;
// 写入BC_TRANSACTION命令
writeTransactionData(BC_TRANSACTION, flags, handle, code, data, nullptr);
if (flags & TF_ONE_WAY) {
// 单向调用:发送后立即返回
return waitForResponse(nullptr, nullptr);
} else {
// 同步调用:等待BR_REPLY
return waitForResponse(reply);
}
}驱动处理(Kernel侧)
驱动的核心函数是binder_ioctl,处理所有ioctl调用:
// binder.c (内核驱动)
static long binder_ioctl(struct file *filp, unsigned int cmd,
unsigned long arg) {
struct binder_proc *proc = filp->private_data;
struct binder_thread *thread;
switch (cmd) {
case BINDER_WRITE_READ: {
struct binder_write_read bwr;
copy_from_user(&bwr, (void __user *)arg, sizeof(bwr));
// 处理写入命令
if (bwr.write_size > 0) {
binder_thread_write(proc, thread,
bwr.write_buffer, bwr.write_size);
}
// 处理读取命令
if (bwr.read_size > 0) {
binder_thread_read(proc, thread,
bwr.read_buffer, bwr.read_size);
}
copy_to_user((void __user *)arg, &bwr, sizeof(bwr));
break;
}
// ... 其他命令
}
}BC_TRANSACTION的处理:
// 简化版流程
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
void __user *buffer, int size) {
while (ptr < end) {
uint32_t cmd = *(uint32_t *)ptr;
switch (cmd) {
case BC_TRANSACTION: {
struct binder_transaction_data tr;
copy_from_user(&tr, ptr, sizeof(tr));
// 1. 查找目标Binder对象
struct binder_node *target_node =
binder_get_node_from_ref(proc, tr.target.handle);
// 2. 分配binder_transaction结构
struct binder_transaction *t = kzalloc(sizeof(*t));
// 3. 分配数据缓冲区(在目标进程的映射区)
struct binder_buffer *buffer =
binder_alloc_buf(target_node->proc, tr.data_size);
// 4. 拷贝数据(唯一的一次拷贝)
copy_from_user(buffer->data, tr.data.ptr.buffer, tr.data_size);
// 5. 处理flat_binder_object(嵌套的Binder对象)
binder_translate_binder(buffer, &tr);
// 6. 将transaction加入目标进程的todo队列
list_add_tail(&t->work.entry, &target_node->proc->todo);
// 7. 唤醒目标进程
wake_up_interruptible(&target_node->proc->wait);
// 8. 返回BR_TRANSACTION_COMPLETE
put_user(BR_TRANSACTION_COMPLETE, (uint32_t __user *)buffer);
break;
}
// ... 其他命令
}
}
}关键步骤:
- 查找目标:根据handle查找目标binder_node
- 分配缓冲区:在目标进程的mmap区域分配buffer
- 拷贝数据:从Client用户空间拷贝到目标进程的内核映射区(唯一的拷贝)
- 转换Binder对象:如果数据中包含Binder对象,需要转换handle/pointer
- 加入队列:将事务加入目标进程的待处理队列
- 唤醒线程:如果目标进程有线程在等待,唤醒它
接收调用(Server侧)
Server端线程通常阻塞在IPCThreadState::joinThreadPool():
// IPCThreadState.cpp
void IPCThreadState::joinThreadPool(bool isMain) {
// 注册线程
mOut.writeInt32(isMain ? BC_ENTER_LOOPER : BC_REGISTER_LOOPER);
do {
// 清空输出缓冲区
mOut.clear();
// 等待命令(阻塞在ioctl)
result = talkWithDriver();
// 处理返回的命令
result = executeCommand(cmd);
} while (result != -ECONNREFUSED && result != -EBADF);
}当驱动有事务时,返回BR_TRANSACTION:
// IPCThreadState.cpp
status_t IPCThreadState::executeCommand(int32_t cmd) {
switch (cmd) {
case BR_TRANSACTION: {
binder_transaction_data tr;
mIn.read(&tr, sizeof(tr));
// 构造Parcel(指向mmap的数据区,无需拷贝)
Parcel buffer;
buffer.ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const size_t*>(tr.data.ptr.offsets),
tr.offsets_size / sizeof(size_t));
// 调用BBinder的transact方法
BBinder* obj = (BBinder*)tr.cookie;
error = obj->transact(tr.code, buffer, &reply, tr.flags);
// 如果不是单向调用,发送BC_REPLY
if ((tr.flags & TF_ONE_WAY) == 0) {
sendReply(reply, 0);
}
break;
}
// ... 其他命令
}
}数据访问:注意buffer.ipcSetDataReference直接引用了mmap区域的数据,Server可以零拷贝地访问参数。
Android 15的Binder新特性
Android 15对Binder进行了多项优化和增强:
1. 冻结通知机制
新增了进程冻结的通知机制,支持应用感知自己被冻结/解冻:
// binder_module.h (Android 15新增)
#define BC_REQUEST_FREEZE_NOTIFICATION // 请求冻结通知
#define BC_CLEAR_FREEZE_NOTIFICATION // 清除冻结通知
#define BR_FROZEN_BINDER // Binder被冻结
#define BR_CLEAR_FREEZE_NOTIFICATION_DONE // 清除通知完成使用场景:当系统冻结后台应用时,可以通过Binder通知应用做清理工作。
2. 单向调用垃圾检测
新增BR_ONEWAY_SPAM_SUSPECT命令,检测滥用单向调用的行为:
case BR_ONEWAY_SPAM_SUSPECT:
// 警告:检测到可疑的单向调用垃圾请求
// 可能是恶意应用在DOS攻击防护:防止恶意应用通过大量单向Binder调用耗尽系统资源。
3. 稳定AIDL支持
Android 15进一步强化了Stable AIDL,确保跨版本的ABI兼容性。
4. 性能优化
- 优化了binder_buffer的分配算法,减少碎片
- 改进了binder_thread的唤醒机制,降低延迟
常见问题
Q1: Binder一次拷贝是如何实现的?
A: 关键是mmap内存映射。Server进程将内核缓冲区映射到自己的用户空间,当Client发送数据时,驱动将数据从Client用户空间拷贝到内核缓冲区(一次拷贝),由于内核缓冲区已映射到Server用户空间,Server可以直接访问,无需第二次拷贝。
Q2: Binder为什么比Socket快?
A: 主要原因:
- 拷贝次数:Binder一次拷贝 vs Socket两次拷贝
- 协议开销:Binder是轻量级协议 vs Socket需要TCP/IP协议栈
- 上下文切换:Binder直接在内核完成路由 vs Socket需要网络层处理
Q3: Binder的安全性体现在哪里?
A:
- 身份验证:
sender_pid和sender_euid由驱动填充,应用无法伪造 - 权限检查:驱动层可以结合SELinux进行细粒度权限控制
- 对象隔离:每个进程只能访问自己的binder_ref,无法直接访问其他进程的对象
Q4: Binder传输大数据(如图片)有限制吗?
A: 有限制。默认mmap大小是(1MB - 8KB),单次传输不能超过此大小。传输大数据的正确方式:
- 使用
ashmem(匿名共享内存)传递文件描述符 - 使用
文件描述符传递,对方通过fd读取数据
Q5: 为什么Binder线程池默认是15个?
A: 这是经验值,平衡了并发能力和资源消耗:
#define DEFAULT_MAX_BINDER_THREADS 15过多线程会消耗内存和调度开销,15个线程对大多数服务足够。可以通过ProcessState::setThreadPoolMaxThreadCount()调整。
实战:追踪Binder调用
让我们通过实际命令追踪一次Binder调用:
1. 查看Binder状态
# 查看系统中所有Binder节点
cat /sys/kernel/debug/binder/state
# 查看某个进程的Binder状态
cat /sys/kernel/debug/binder/proc/<pid>
# 查看Binder事务记录
cat /sys/kernel/debug/binder/transaction_log2. 使用Systrace追踪
# 抓取Binder trace
systrace.py -t 10 binder gfx view wm am -o trace.html
# 在Chrome中打开trace.html,搜索"binder transaction"3. 通过logcat查看Binder日志
# 开启Binder日志(需要工程版ROM)
adb shell setprop log.tag.BpBinder VERBOSE
adb shell setprop log.tag.BBinder VERBOSE
# 查看日志
adb logcat | grep -i binder总结
Binder作为Android的核心IPC机制,其设计充满智慧:
设计亮点:
- ✅ 一次拷贝:通过mmap内存映射实现,性能优于传统IPC
- ✅ 面向对象:天然支持对象引用、接口调用、生命周期管理
- ✅ 强安全性:驱动级身份验证,无法伪造UID/PID
- ✅ 稳定可靠:死亡通知、引用计数,服务异常能及时感知
核心机制:
- mmap映射:建立用户空间到内核空间的共享内存,实现零拷贝访问
- BC/BR协议:基于命令的轻量级协议,减少通信开销
- 驱动管理:在内核层统一管理所有IPC,提供安全保障
学习路径:
- 理解Binder的整体架构和设计理念
- 掌握核心数据结构和工作流程
- 阅读ProcessState、IPCThreadState的源码实现
- 学习AIDL和ServiceManager(下一篇)
- 实践:编写自己的Binder服务
参考源码
系列文章
- 上一篇:Android 15网络子系统深度解析(二):NetworkPolicy流量控制、VPN框架与网络优化全解析
- 下一篇:Android 15 ServiceManager与Binder服务注册深度解析
欢迎来我中的个人主页找到更多有用的知识和有趣的产品